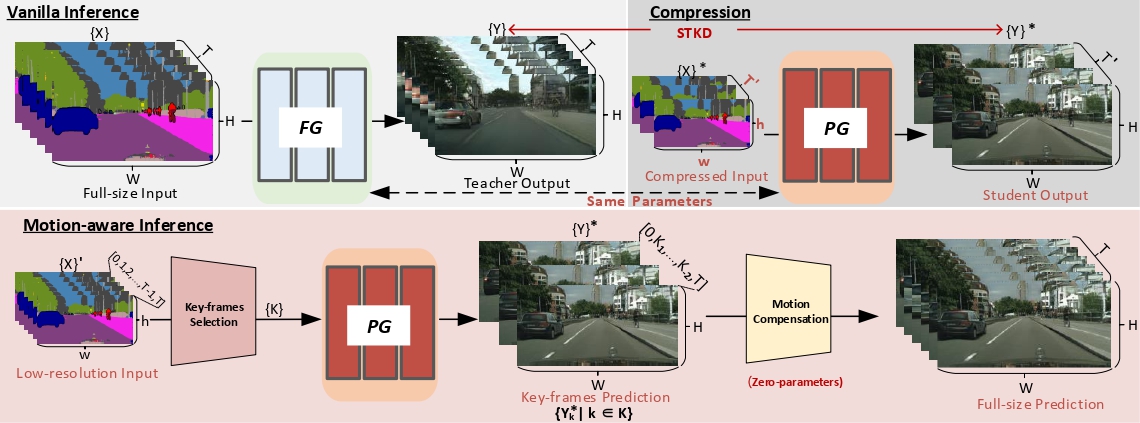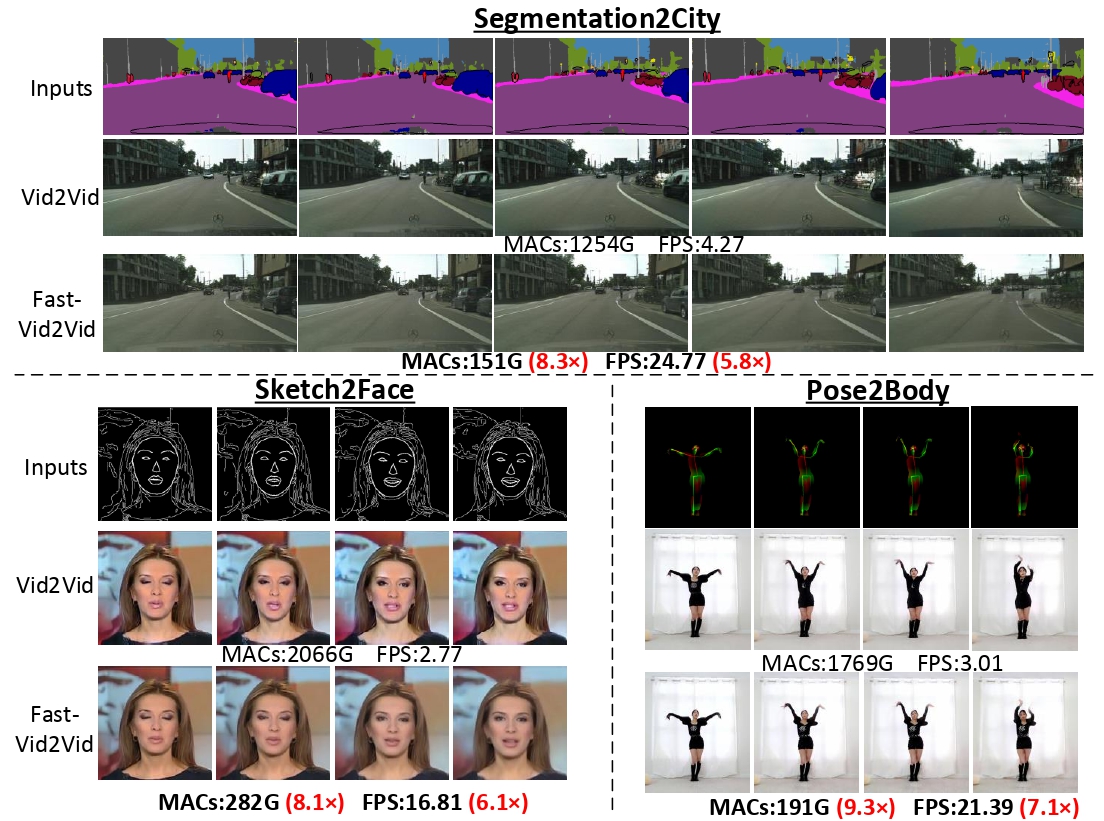
Video-to-Video synthesis (Vid2Vid) has achieved remarkable results in generating a photo-realistic video from a sequence of semantic maps. However, this pipeline suffers from high computational cost and long inference latency, which largely depends on two essential factors: 1) network architecture parameters, 2) sequential data stream. Recently, the parameters of image-based generative models have been significantly compressed via more efficient network architectures. Nevertheless, existing methods mainly focus on slimming network architectures and ignore the size of the sequential data stream. Moreover, due to the lack of temporal coherence, image-based compression is not sufficient for the compression of the video task. In this paper, we present a spatial-temporal compression framework, Fast-Vid2Vid, which focuses on data aspects of generative models. It makes the first attempt at time dimension to reduce computational resources and accelerate inference. Specifically, we compress the input data stream spatially and reduce the temporal redundancy. After the proposed spatial-temporal knowledge distillation, our model can synthesize key-frames using the low-resolution data stream. Finally, Fast-Vid2Vid interpolates intermediate frames by motion compensation with slight latency. On standard benchmarks, Fast-Vid2Vid achieves around real-time performance as 20 FPS and saves around 8× computational cost on a single V100 GPU.
Vid2Vid Synthesis proposes a large netowrk to syntheisize the videos using semantic sequences.
CA Compression compresses GAN by applying the salient content for pruning the unimportant architectures.
CAT Compression proposes an efficient convoltional block and a new knowledge distillation approach for compressing the generator.
NAS Compression compresses GAN by adopting nerual architecture search techneque to select the most effective set of channels in each convolution layer.
@inproceedings{zhuo2022fast,
author = {Zhuo, Long and Wang, Guangcong and Li, Shikai and Wu, Wanye and Liu, Ziwei},
title = {Fast-Vid2Vid: Spatial-Temporal Compression for Video-to-Video Synthesis},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2022},
}